Copyright Red Hat 2014 - 2020
This document is licensed under the "Creative Commons Attribution-ShareAlike (CC-BY-SA) 3.0" license.
This is the jgroups-raft manual. It provides information about
-
Design and architecture
-
Configuration and use
of jgroups-raft.
Bela Ban, Kreuzlingen Switzerland 2015
1. Overview
The jgroups-raft project is an implementation of Raft in JGroups.
It provides a consensus based system where leader election and changes are committed by consensus (majority agreement). A fixed number of nodes form a cluster and each node is a state machine. A leader is elected by consensus and all changes happen through the leader which replicates them to all nodes, which add them to their persistent log.
Because Raft guarantees that there’s only ever one leader at any time, and changes are identified uniquely, all state machines receive the same ordered stream of updates and thus have the exact same state.
Raft favors consistency over availability; in terms of the Cap theorem, jgroups-raft is a CP system. This means jgroups-raft is highly consistent, and the data replicated to nodes will never diverge, even in the face of network partitions (split brains).
In case of a network partition, in a cluster of N nodes, at least N/2+1 nodes have to be running for the
system to be available.
If for example, in a 5 node cluster, 2 nodes go down, then the system can still commit changes and elect leaders as 3 is still the majority. However, if another node goes down, the system becomes unavailable and client requests will be rejected. (Depending on configuration, there may still be some limited form of read-only availability.)
By implementing jgroups-raft in JGroups, the following benefits can be had:
-
Transports already available: UDP, TCP
-
Contains thread pools, priority delivery (OOB), batching etc
-
-
Variety of discovery protocols
-
Encryption, authentication, compression
-
Fragmentation, reliability over UDP
-
Multicasting for larger clusters
-
Failure detection
-
Sync/async cluster RPCs
The code required to be written for a full Raft implementation is smaller than if it had been implemented outside of JGroups.
The feature set of jgroups-raft includes
-
Leader election and append entries functionality by consensus
-
Persistent log (using LevelDB)
-
Dynamic addition and removal of cluster nodes
-
Cluster wide atomic counters
-
Replicated hash maps (replicated state machines)
1.1. Architecture
The architecture of jgroups-raft is shown below.
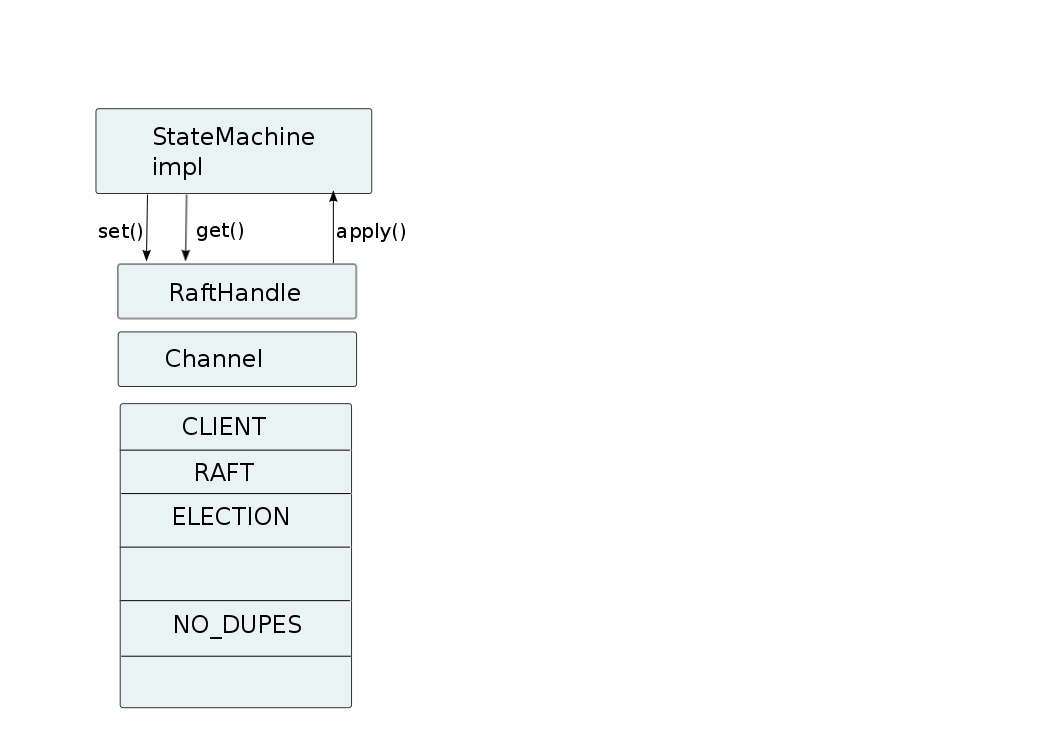
The components that make up jgroups-raft are
-
A JGroups protocol stack with jgroups-raft specific protocols added:
-
NO_DUPES: makes sure that a jgroups-raft node does not appear in a view more than once -
ELECTION: handles leader election -
RAFT: implements the Raft algorithm, ie. appending entries to the persistent log, committing them, syncing new members etc -
REDIRECT(not shown): redirects requests to the leader -
CLIENT: accepts client requests over a socket, executes them and sends the results back to the clients
-
-
Channel: this is a regular JGroupsJChannelorForkChannel -
RaftHandle: the main class for users of jgroups-raft to interact with -
StateMachine: an implementation ofStateMachine. This is typically a replicated state machine. jgroups-raft ships with a number of building blocks implementingStateMachinesuch asCounterServiceorReplicatedStateMachine.
The figure above shows one node in a cluster, but the other nodes have the same setup except that every node is required
to have a different raft_id (defined in RAFT). This is a string which defines one cluster member; all members
need to have different raft_ids (more on this later).
2. Using jgroups-raft
2.1. Cluster members and identity
Each cluster member has an address (a UUID) assigned by JGroups and a raft_id which needs to be assigned by the user.
The latter is a string (e.g. "A") which needs to be unique in the entire cluster. In other words, the raft_id is the
identity of a member for the sake of jgroups-raft.
A Raft cluster has a fixed size, so that a majority can be computed for leader election and appending of entries. The
members allowed into the cluster is defined in RAFT.members, e.g.
<raft.RAFT members="A,B,C" raft_id="${raft_id:undefined}"/>This defines a cluster of 3 members: "A", "B" and "C" (whose majority is 2).
These are the raft_id attributes of the 3 members, so attribute raft_id in the example above needs to be one of them.
If we don’t start this member with the system property -Draft_id=X (where X needs to be "A", "B", or "C"),
then the member will start up as "undefined" is not a member of {"A", "B", "C"}.
|
|
Note that while RAFT ensures that non-members cannot join a cluster, the NO_DUPES protocol makes sure that
no duplicate member can join. Example: if we have RAFT.members="A,B,C" and actual members "A" and "B" joined, then
a join attempt by a member with duplicate name "B" will be rejected and that member won’t be able to join.
|
Attribute raft_id is also used to define the location of the persistent log; unless log_name is defined in
RAFT, the location is computed as <temp_dir>/<raft_id>.log, e.g. /tmp/A.log.
Note that members can be added and removed dynamically (without taking the entire cluster down, changing the configuration and restarting it), see Adding and removing members dynamically.
2.2. RaftHandle
As shown in The architecture of jgroups-raft, RaftHandle is the main class users will be dealing with. It provides methods to change
state (append entries) in the replicated state machines, and a state machine can be registered with it. The state machine
will be initialized at startup and updated by jgroups-raft whenever there is a change.
A successful change is committed to the persistent logs of all cluster members and applied to their state machines, so all state machines have exactly the same state.
2.2.1. Creation
An instance of RaftHandle is associated with exactly one JGroups channel, and can be created as follows:
JChannel ch=new JChannel("/home/bela/raft.xml");  RaftHandle handle=new RaftHandle(ch, this);
RaftHandle handle=new RaftHandle(ch, this);  ch.connect("raft-cluster");
ch.connect("raft-cluster"); 
| A new JGroups channel is created (see the JGroups manual for details on the JGroups API) | |
A RaftHandle instance is created over the channel (which must be non-null). The second argument is an implementation
of StateMachine. If null, no changes will be applied. The state machine can be set with stateMachine(StateMachine sm). |
|
| The channel is connected which causes the member to join the cluster |
2.2.2. Making changes
The setX() methods can be used to make changes:
byte[] set(byte[] buf, int offset, int length) throws Exception;
byte[] set(byte[] buf, int offset, int length, long timeout, TimeUnit unit) throws Exception;
CompletableFuture<byte[]> setAsync(byte[] buf, int offset, int length); | Synchronous change; the caller will be blocked until the change has been forwarded to the leader, which sends it to all cluster members which apply it to their persistent logs and ack the change back to the leader. Once the leader gets a majority of acks, it commits the change to its own log, applies it to its state machine and returns the response to the caller. The state machines thus only contain committed changes. | |
Same as above, except that this call is bounded with a timeout. If it elapses before a majority of acks have been
received, a TimeoutException will be thrown. |
|
Asynchronous change; this method returns immediately with a CompletableFuture which can be used to retrieve the
result later, or to provide some code that’s executed as soon as the result is available (e.g. whenComplete()). |
The contents of the request and response buffers is application specific.
For example, if we implemented a replicated hash map, then a request could be a put(key,value). The put()
would have to be serialized into the buffer, as well as the key and the value.
When committing the change, every state machine needs to de-serialize the buffer into a put(key,value) and apply it to
its state (see Implementing a StateMachine). If there is a return value to the put() call, e.g. the previous value
associated with key, then it will be serialized into a buffer and returned as result of one of the setX() calls.
2.2.3. Implementing a StateMachine
StateMachine is an interface and is defined as follows:
public interface StateMachine {
byte[] apply(byte[] data, int offset, int length) throws Exception;
void readContentFrom(DataInput in) throws Exception;
void writeContentTo(DataOutput out) throws Exception;
}This method is called whenever a log entry is committed. The buffer’s contents are application specific (e.g this
could be a serialized put(key,value) as discussed above. If there is a return value of applying the change to the
state machine, it needs to be serialized so that it can be returned to the caller (e.g. a client). |
|
This method is called when RAFT needs to initialize a state machine from a snapshot (a dump of a state
machine’s contents to an external stream (e.g. a file)). The writeContentTo() method below wrote the contents
to a file before, in an application specific format, and this method now needs to read the contents back into the
state machine. |
|
This method is the opposite of readContentFrom() and writes the contents of this state machine to a stream
(e.g. a file). |
2.2.4. Snapshotting and state transfer
All cluster members maintain a persistent log and append all changes as log entries to the end of the log. To prevent
logs from growing indefinitely, a snapshot of the state machine can be made and the log truncated. This is done
(programatically) with method snapshot(), or declaratively (see below).
This method calls StateMachine.writeContentTo() to dump the state of the state machine into a snapshot file and then
truncates the log. New members who don’t have a log yet are initialized by sending them the snapshot first. After that,
they will catch up via the regular Raft mechanism.
Logs can be snapshot automatically by setting RAFT.max_log_size to the max number of bytes that a log is allowed to
grow to until a snapshot is taken.
2.2.5. Miscellaneous methods
Other methods in RaftHandle include:
- leader()
-
Returns the address of the current Raft leader, or null if there is no leader (e.g. in case there was no majority to elect a leader)
- isLeader()
-
Whether or not the current member is the leader
- addRoleListener(RAFT.RoleChange listener)
-
Allows to register a
RoleChangelistener which is notified when the current member changes its role (Leader,Follower,Candidate) - currentTerm()
-
Returns the current term (see Raft for details)
- lastApplied()
-
Returns the index of the last log entry that was appended to the log
- commitIndex()
-
Returns the index of the last log entry that was committed
- raft()
-
Returns a reference to the
RAFTprotocol in the current member’s stack. Provided for experts who need to accessRAFTdirectly. - raftId(String id)
-
Used to set the
raft_idprogrammatically (note that this can also be done by settingraft_idinRAFTin the XML configuration. For example, the following code setsraft_idfrom the command line:
protected void start(String raft_id) throws Exception {
JChannel ch=new JChannel("raft.xml").name(raft_id);
RaftHandle handle=new RaftHandle(ch, this).raftId(raft_id);
ch.connect("raft-cluster");  }
public static void main(String[] args) throws Exception {
new bla().start(args[0]);
}
}
public static void main(String[] args) throws Exception {
new bla().start(args[0]);
}The raft_id can for example be passed to the program as an argument |
|
The channel is created and its logical name set to be the same as raft_id. This is not necessary, but convenient. |
|
Now raft_id can be set via RaftHandle.raftId(String id). |
2.3. Configuration
The configuration of a member is either done declaratively via an XML config file or programmatically. Refer to the JGroups documentation for details.
A sample XML configuration file is shown below (edited for brevity):
<config xmlns="urn:org:jgroups"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/jgroups.xsd">
<UDP
mcast_addr="228.5.5.5"
mcast_port="${jgroups.udp.mcast_port:45588}"/>
<PING />
<MERGE3 />
<FD_SOCK/>
<FD_ALL/>
<VERIFY_SUSPECT timeout="1500" />
<pbcast.NAKACK2 xmit_interval="500"
discard_delivered_msgs="true"/>
<UNICAST3 xmit_interval="500"
max_msg_batch_size="500"/>
<pbcast.STABLE desired_avg_gossip="50000"
max_bytes="4M"/>
<raft.NO_DUPES/>
<pbcast.GMS print_local_addr="true" join_timeout="2000"
view_bundling="true"/>
<UFC max_credits="2M" min_threshold="0.4"/>
<MFC max_credits="2M" min_threshold="0.4"/>
<FRAG2 frag_size="60K" />
<raft.ELECTION election_min_interval="100" election_max_interval="500"/>
<raft.RAFT members="A,B,C,D" raft_id="${raft_id:undefined}"/>
<raft.REDIRECT/>
<raft.CLIENT bind_addr="0.0.0.0" />  </config>
</config>NO_DUPES: checks that joining a new member doesn’t lead to duplicate raft_ids in the membership. Rejects the
JOIN if it would. Must be placed somewhere below GMS |
|
ELECTION: this protocol implements leader election, as defined in Raft. It is independent from RAFT and could
(and may, in the future) be replaced with a different election protocol. Attributes election_min_interval and
election_max_interval define the range from which jgroups-raft picks a random election timeout. |
|
RAFT: the main protocol implementing log appending and committing, handling state machine updates, snapshotting etc.
Attribute members defines the (fixed) membership (may still be redfined by addServer/removeServer log entries
when initializing a member from the persistent log). Attribute raft_id defines the ID of the current member (needs
to be an element of members, as discussed earlier). |
|
REDIRECT is used to redirect requests to the current Raft leader, or to throw an exception if no member is leader |
|
CLIENT listens on a socket (port 1965 by default) for client requests, executes them and sends the result back
to the clients. Currently, addServer and removeServer has been implemented. |
This is a regular JGroups XML configuration, except that jgroups-raft added a few additional protocols.
2.4. Adding and removing members dynamically
The RAFT protocol provides methods addServer(String raft_id) and removeServer(String raft_id) to add and remove
servers from the static membership (defined by RAFT.members). Only one server at a time can be added and removed, and
adding or removing a server needs a majority ack to be committed.
Both methods are exposed via JMX, so jconsole could be used. However, jgroups-raft also provides a script
(client.sh) to do this in a more convenient way. The script uses Client to connect to a member’s CLIENT protocol
running at localhost:1965 (can be changed). The request is then forwarded to the current leader.
The steps to add a member are as follows (say we have RAFT.members="A,B,C" and want to add "D"):
-
Call
bin/client.sh -add D-
If needed,
-port PORTor-bind_addr ADDRcan be given, e.g. if we need to reach a member running on a different host
-
-
Once
A(the leader) processedaddServer("D"), everybody’sRAFT.membersis"A","B","C","D" -
At this point, the XML configuration files should be updated so that
RAFT.members="A,B,C,D" -
If not, members will read the correct membership when getting initialized by their logs
-
A new member
Dcan now be started (its XML config needs to have the correctmembersattribute !)
3. Building blocks
Similar to JGroups' building blocks, jgroups-raft also has building blocks, which provide additional functionality on
top of a RaftHandle. They are typically given a JChannel, create a RaftHandle and register themselves as
StateMachine with the handle. Building blocks offer a different interface to the users, e.g. a replicated hashmap
with puts and gets, or a distributed counter or lock.
3.1. ReplicatedStateMachine
ReplicatedStateMachine is a key-value store replicating its contents to all cluster members. Contrary to the JGroups
equivalent (ReplicatedHashMap), changes are replicated by consensus and logged to a persistent log.
While the JGroups version is allowed to make progress during network partitions, and users need to merge possibly
diverging state from different partitions after a partition heals, ReplicatedStateMachine will allow progress only in
the majority partition, so no state merging needs to be done after a partition heals.
Not having to merge state is certainly simpler, but comes at the expense of availability: if N/2+1 members leave or
split into different partitions, ReplicatedStateMachine will be unavailable (all requests will time out).
However, the advantage is that the members' states will never diverge.
ReplicatedStateMachine requires a JChannel in its constructor and has put(), get() and remove() methods.
The code below shows how to create an instance of ReplicatedStateMachine and add an element to it:
protected void start(String raft_id) throws Exception {
JChannel ch=new JChannel("raft.xml").name(raft_id);
ReplicatedStateMachine<String,String> rsm=new ReplicatedStateMachine<>(ch);
rsm.raftId(raft_id);
ch.connect("rsm-cluster");
rsm.put("name", "Bela");
}There’s a demo ReplicatedStateMachineDemo which can be used to interactively use ReplicatedStateMachine.
3.2. CounterService
CounterService provides a replicated counter which can get be set, get and compare-and-set, implementing JGroups'
Counter interface:
public interface Counter {
public long get();
public void set(long new_value);
public boolean compareAndSet(long expect, long update);
public long incrementAndGet();
public long decrementAndGet();
public long addAndGet(long delta);
}A Counter implementation is created via the CounterService building block (edited):
public class CounterService implements StateMachine {
public CounterService(Channel ch);
public long replTimeout();
public CounterService replTimeout(long timeout);
public boolean allowDirtyReads();
public CounterService allowDirtyReads(boolean flag);
public CounterService raftId(String id);
/**
* Returns an existing counter, or creates a new one if none exists
* @param name Name of the counter, different counters have to have different names
* @param initial_value The initial value of a new counter if there is no existing counter.
* Ignored if the counter already exists
* @return The counter implementation
*/
public Counter getOrCreateCounter(String name, long initial_value) throws Exception;
/**
* Deletes a counter instance (on the coordinator)
* @param name The name of the counter. No-op if the counter doesn't exist
*/
public void deleteCounter(String name) throws Exception;
}CounterService is mainly used to get an existing or create a new Counter implementation (getOrCreateCounter()), or
to delete an existing counter (deleteCounter()).
To create an instance of CounterService, a JChannel has to be passed to the constructor. The sample code below
shows how to use this:
protected void start(String raft_id) throws Exception {
JChannel ch=new JChannel("raft.xml").name(raft_id);
CounterService cs=new CounterService(ch);
ch.connect("counter-cluster");
Counter counter=cs.getOrCreateCounter("mycounter", 1);
counter.incrementAndGet();
counter.compareAndSet(2, 5);
long current_value=counter.get();
}First a CounterService is created and given a reference to a channel |
|
| Once the member has joined the cluster, we create a counter named "mycounter" with an initial value of 1 | |
| The counter is then incremented to 2 | |
| Now a compare-and-set operation sets the counter to 5 if it was 2 | |
| The last operation fetches the current value of "mycounter" |
Any member in the cluster can change the same counter and all operations are ordered by the Raft leader, which causes the replicated counters to have exactly the same value in all members.
Comparing this to the JGroups equivalent, a jgroups-raft counter never diverges in different members, again at the expense of availability. In the JGroups version, counters are always available, but may diverge, e.g. in a split brain scenario, and have to be reconciled by the application after the split brain is resolved.
There’s a demo CounterServiceDemo which can be used to interactively manipulate replicated counters.
3.2.1. Reads and consensus
Currently (as of jgroups-raft version 0.2), reading a counter is by default dirty, meaning that a read may return a stale value.
This can be changed by calling counter_service.allowDirtyReads(false).
However, this inserts a dummy read log entry which returns the value of counter when committed. Since this dummy entry is ordered correctly wrt writes in the log, it will always return correct values.
The cost is that reads take up space in the persistent logs and that we need consensus (majority) for reads. In the next release of jgroups-raft, the mechanism for client reads as suggested in the Raft paper will be implemented. See Issue 18 for details.
|
|
Non-dirty reads has not yet been implemented in ReplicatedStateMachine.
|
3.3. Singleton service
A singleton service is a service which is supposed to run only once in an entire cluster. Typically, in JGroups, a
singleton service is started on the first member of a cluster. For example, if we have {A,B,C,D,E}, the singleton
service (or services) would be running on A.
If we have a partition, such that the cluster falls apart into {A,B,C} and {D,E}, then an additional singleton
would be started on D, as D became coordinator and doesn’t know {A,B,C} didn’t leave, but were partitioned away
instead.
When the partition ends, if D is not coordinator anymore, it would stop its singleton services.
If multiple singletons (as provided by JGroups, e.g. during a network split) cannot be tolerated by the application, and the application has a requirement that at most one singleton service can be running (better none than two), jgroups-raft can be used.
The mechanism to implement singleton services in jgroups-raft is leader election: it is guaranteed that at most one leader exists in a given cluster at the same time. This is exactly what we need for singletons. The code below shows how to do this:
JChannel ch=null;
RaftHandle handle=new RaftHandle(ch, this);
handle.addRoleListener(role -> {
if(role == Role.Leader)
// start singleton services
else
// stop singleton services
});A RaftHandle is created over a channel |
|
A RAFT.RoleChange callback is registered with the handle. Alternatively, addRoleListener() could be called
directly on an instance of RAFT retrieved from the protocol stack associated with the given channel |
|
| When we become the Raft leader, the singleton services can be started, when not, they should be stopped (if running) |
4. List of protocols
This chapter describes the most frequently used protocols, and their configuration.
Meanwhile, we recommend that users should copy one of the predefined configurations (shipped with jgroups-raft), e.g.
raft.xml, and make only minimal changes to it.
4.1. NO_DUPES
This protocol prevents duplicate members from joining the cluster. The protocol needs to be located somewhere below
GMS.
NO_DUPES catches JOIN requests from a joiner to the JGroups coordinator and checks if the joiner’s raft_id is
already contained in the current membership, and rejects the JOIN if this is the case.
For example, if we have current members {A,B} and another member with raft_id "B" joins, then the joiner would
get the following exception when trying to join the cluster:
------------------------------------------------------------------- GMS: address=B, cluster=cntrs, physical address=127.0.0.1:64733 ------------------------------------------------------------------- Exception in thread "main" java.lang.Exception: connecting to channel "cntrs" failed at org.jgroups.JChannel._connect(JChannel.java:570) at org.jgroups.JChannel.connect(JChannel.java:294) at org.jgroups.JChannel.connect(JChannel.java:279) at org.jgroups.raft.demos.CounterServiceDemo.start(CounterServiceDemo.java:32) at org.jgroups.raft.demos.CounterServiceDemo.main(CounterServiceDemo.java:163) Caused by: java.lang.SecurityException: join of B rejected as it would create a view with duplicate members (current view: [B|1] (2) [B, A]) at org.jgroups.protocols.pbcast.ClientGmsImpl.isJoinResponseValid(ClientGmsImpl.java:187) at org.jgroups.protocols.pbcast.ClientGmsImpl.installViewIfValidJoinRsp(ClientGmsImpl.java:153) at org.jgroups.protocols.pbcast.ClientGmsImpl.joinInternal(ClientGmsImpl.java:111) at org.jgroups.protocols.pbcast.ClientGmsImpl.join(ClientGmsImpl.java:41) at org.jgroups.protocols.pbcast.GMS.down(GMS.java:1087) at org.jgroups.protocols.FlowControl.down(FlowControl.java:353) at org.jgroups.protocols.FlowControl.down(FlowControl.java:353) at org.jgroups.protocols.FRAG2.down(FRAG2.java:136) at org.jgroups.protocols.RSVP.down(RSVP.java:153) at org.jgroups.protocols.pbcast.STATE_TRANSFER.down(STATE_TRANSFER.java:202) at org.jgroups.protocols.raft.ELECTION.down(ELECTION.java:112) at org.jgroups.protocols.raft.RAFT.down(RAFT.java:442) at org.jgroups.protocols.raft.REDIRECT.down(REDIRECT.java:103) at org.jgroups.stack.ProtocolStack.down(ProtocolStack.java:1038) at org.jgroups.JChannel.down(JChannel.java:791) at org.jgroups.JChannel._connect(JChannel.java:564) ... 4 more [mac] /Users/bela/jgroups-raft$
The error message is SecurityException: join of B rejected as it would create a view with duplicate members (current view: [B|1] (2) [B, A]),
which shows that view {B,A} already contains a member with raft_id B, and so the JOIN request of the new member
is rejected.
4.2. ELECTION
ELECTION is the protocol which performs leader election, as defined by Raft.
Its attributes define the election timeout and the heartbeat interval (see Raft for details).
| Name | Description |
|---|---|
election_max_interval |
Max election interval (ms). The actual election interval is computed as a random value in range [election_min_interval..election_max_interval] |
election_min_interval |
Min election interval (ms) |
heartbeat_interval |
Interval (in ms) at which a leader sends out heartbeats |
4.3. RAFT
RAFT is the main protocol in jgroups-raft; it implements log appending and committing, snapshotting and log compaction,
syncing of new members and so on.
| Name | Description |
|---|---|
log_args |
Arguments to the log impl, e.g. k1=v1,k2=v2. These will be passed to init() |
log_class |
The fully qualified name of the class implementing Log |
log_name |
The name of the log. The logical name of the channel (if defined) is used by default. Note that logs for different processes on the same host need to be different |
max_log_size |
Max number of bytes a log can have until a snapshot is created |
members |
List of members (logical names); majority is computed from it |
raft_id |
The identifier of this node. Needs to be unique and an element of members. Must not be null |
resend_interval |
Interval (ms) at which AppendEntries messages are resent to members which haven’t received them yet |
snapshot_name |
The name of the snapshot. By default, <log_name>.snapshot will be used |
4.4. REDIRECT
The REDIRECT protocol needs to be somewhere above RAFT. It keeps track of the current Raft leader and redirects
requests to the right leader. If there is no leader, e.g. because there’s no majority to elect one, an exception will
be thrown.
4.5. CLIENT
CLIENT listens on a socket for client requests. When a request is received, it is sent down where it will be forwarded
(by REDIRECT) to the current leader which executes the request. The responses is then sent back to the client.
| Name | Description |
|---|---|
bind_addr |
The bind address which should be used by the server socket. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL, NON_LOOPBACK, match-interface, match-host, match-address |
idle_time |
Number of ms a thread can be idle before being removed from the thread pool |
max_threads |
Max number of threads in the thread pool |
min_threads |
The min threads in the thread pool |
port |
Port to listen for client requests |